Leveraging In-Flight Message Count to dynamically scale your ECS – EC2 Tasks to bring optimal message processing efficiency alongside cost efficiency.
Intro
In AWS SQS You have Standard and FIFO Queue types. Scaling based on the number of messages in SQS is straightforward since we do not have to think about the order of the messages being processed so it guarantees maximum throughput. In simple terms, if you scale the listeners (ECS Tasks in our context) queue messages will process faster. However, in the FIFO queue type, there is a slight difference. The main use case of using a FIFO queue is to ensure your Messages are delivered and processed in the exact order they are sent.
In such a scenario how can you scale your message consumers?
Default Pattern provided by AWS
MessageGroupID is the default solution for such a requirement. Let’s explore more about MessageGroupID
MessageGroupId is the tag that specifies that a message belongs to a specific message group. Messages that belong to the same message group are always processed one by one, in a strict order relative to the message group (however, messages that belong to different message groups might be processed out of order).
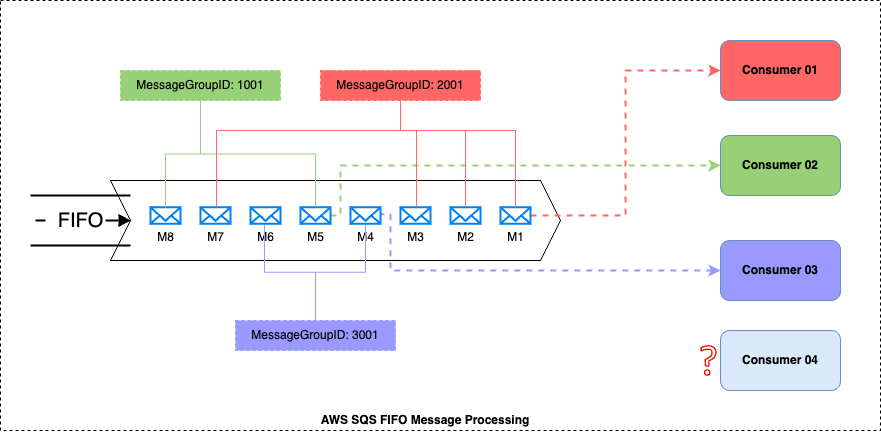
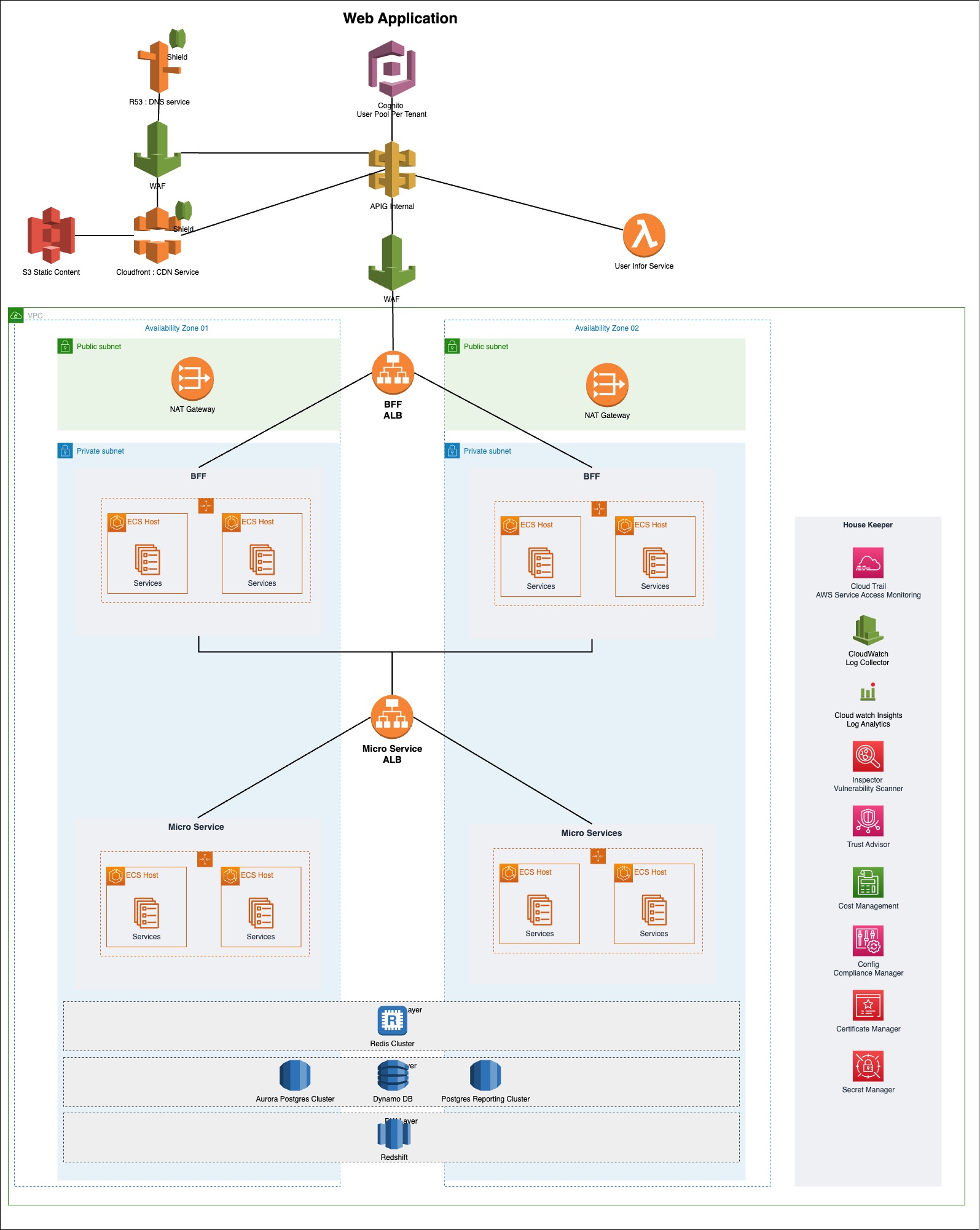
Key Components of the above diagram
- There are 8 messages in the FIFO queue
- Those 8 messages belongs to three MessageGroupIDs
- MessageGroupID 1001 – {M8, M5,}
- MessageGroupID 2001 – {M7, M3, M2, M1}
- MessageGroupID 3001 – {M6, M4}
- There are 4 consumers listening to the FIFO queue
How the messages will process with the above setup
- Message Consumers 01 will start consuming the MessageGroupID 2001 related messages in the FIFO order (Start with M1)
- Message Consumers 02 will start consuming the MessageGroupID 1001 related messages in the FIFO order (Start with M5)
- Message Consumers 03 will start consuming the MessageGroupID 3001 related messages in the FIFO order (Start with M4)
- All the 3 consumers will process messages in parallel
- Message Consumer 04 is in a idle state
PAIN with the Default Pattern
Let’s talk about a use-case and the issues you might encounter in the previously explained configuration.
Use-case
- You have 100,000 messages in a FIFO queue
- Consumers of the queue are ECS – EC2 tasks
- Consumer might take 10 Seconds to process each message
- You have configured 30 as the desired task count
- In the queue statistics, Messages in flight (not available to other consumers) number shows as 10
Outcome
- Only 10 consumers are processing messages in parallel
- 10 unique MessagegroupIDs present in the queue which contain 100,000 messages
- 20 Consumers are in idle state (Unused resources) – Low Cost efficiency & High Performance Efficiency
Let’s think on when we had configured the desire task count to 5
- Only 5 consumers are processing messages in parallel
- 10 unique MessagegroupIDs present in the queue which contain 100,000 messages
- Only 5 MessageGroupID related messages are been processed where it can scale up to 10 to get the optimal eiffciency for message processing – High Cost efficiency & Low Performance Efficiency
Challenge: Bring a balance between Cost & Performance, when we process messages in a FIFO with multiple MessageGroupIDs & consumers.
ANALYSIS
What other metrics we can used to overcome this challenge?
In-Flight Message came into the rescue.
What do you mean by In-Flight Message in SQS
An Amazon SQS message has three basic states:
- Sent to a queue by a producer.
- Received from the queue by a consumer.
- Deleted from the queue.
A message is considered to be stored after it is sent to a queue by a producer, but not yet received from the queue by a consumer (that is, between states 1 and 2). A message is considered to be in flight after it is received from a queue by a consumer, but not yet deleted from the queue (that is, between states 2 and 3). There is a quota to the number of in flight messages. For FIFO queues, there can be a maximum of 20,000 in flight messages (received from a queue by a consumer, but not yet deleted from the queue).
In lamen terms if we take consumers process one message at a time, then In-Fight messages represent the number of consumers actively processing messages. In my previous example it was 10.
SOLUTION
Utilizing the In-Flight Message Count for Dynamic Scaling
Simple algorithm came to rescue
- X → In-Flight Message Count → ApproximateNumberOfMessagesNotVisible Metric
- Y → Number of Tasks Listening to the Queue → Desired task count
Scenario 01 – (X<Y) Idle Resources (Cost Efficiency)
Understanding the Scale-Down mechanism implemented herein is straightforward. Primarily, the system evaluates the count of in-flight messages, and if this count consistently remains lower than the number of tasks deployed, a scale-down operation is initiated. The scale-down process is governed by a target tracking policy, which orchestrates a gradual reduction in the number of tasks.
Scenario 02 – (X=Y) Improving the message processing Efficiency
In the Scale-Up scenario, if we add few more tasks, there might be a chance we can process new messages with different MessageGroupIDs. Hence we introduced spare tasks, spare tasks are idle ECS tasks that are ready to process incoming messages. The specific number of spare tasks required may vary depending on the desired latency, but typically 1 or 2 spare tasks are adequate for efficient scaling.
In our final solution, we introduced set of components to manage this dynamic scaling process.
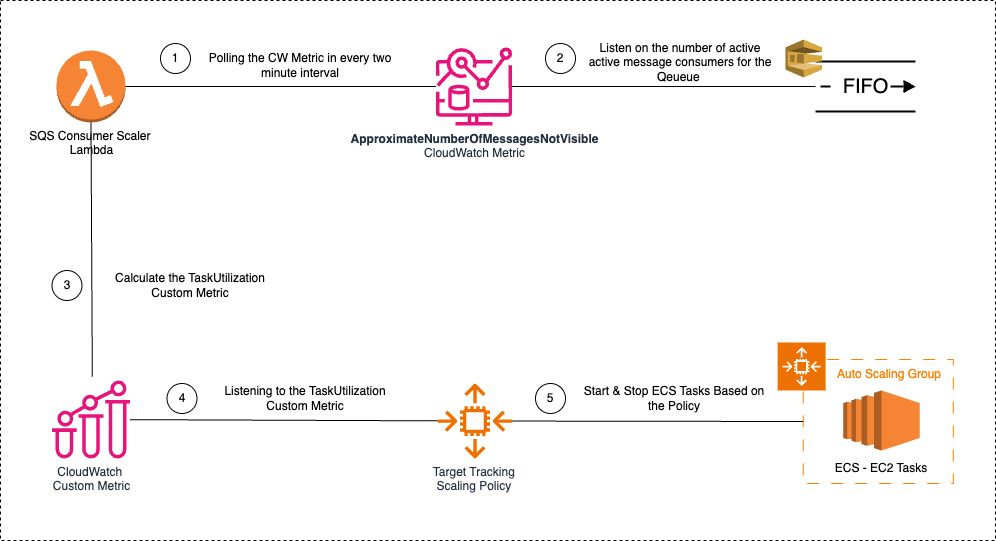
Key Item here is the Calculating the Task Utilization Custom Metric. You can fine tune this calculation as per your requirement.
TaskUtilization Percentage
The TaskUtilization metric is computed through a custom process utilizing the ApproximateNumberOfMessagesNotVisible value and the current task count. A Lambda function is specifically developed for this purpose, invoking the CloudWatch Metrics API to retrieve five data points representing the one-minute average values for ApproximateNumberOfMessagesNotVisible of the designated FIFO queue. The maximum average value among these data points is then determined.
Subsequently, the desired_task_count is calculated by adding the maximum average for ApproximateNumberOfMessagesNotVisible to the number of spare tasks. The taskUtilization percentage is then derived by multiplying 100 with the ratio of desired_task_count to the number of currently running tasks. This calculated value is crucial for dynamically scaling the ECS task count.
![]()
CONCLUSION
The solution helped us to improve the FIFO processing efficiency by 5X and provide significant cost efficiency as well. You can further bring changes to above solution like, Start and Stop this Scaling Policy only when OldestMessage hit a threshold or based on message count. Also, adjust the max consumer count based on how other services behave (ex: RDS performance if the task is only depend on the RDS).
To warp up, above approach might not be the only solution to overcome this challenge, we are continuously evaluating different approaches to bring more cost and performance efficiency to our FIFO message consumers.
References
- https://docs.aws.amazon.com/autoscaling/ec2/userguide/as-using-sqs-queue.html