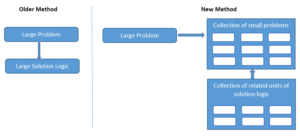
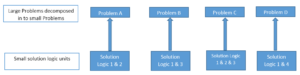
This marks the inaugural article in a series titled ‘Initiate your SaaS journey by taking small steps and steadily enhancing capabilities with AWS‘, The series delves into the challenges faced during the early years of my SaaS industry journey (Velaris.io) and how these obstacles were overcome through a gradual improvement approach with AWS capabilities and Practical Engineering.
In this article, we will explore a specific use case where we encountered a substantial 140% increase in RDS costs compared to the previous month’s bill in AWS. We will delve into the design changes we implemented in our architecture to effectively resolve this cost surge.
RDS Costs Surged by 140% Between November and December
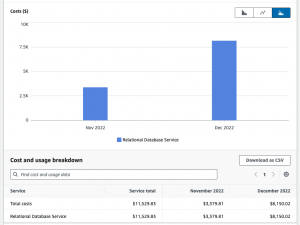
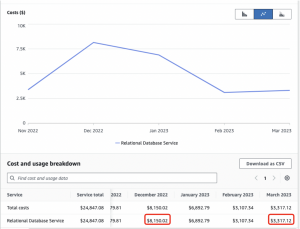
As depicted in the chart, there was a notable 1.5X rise in RDS cost between November 2022 (3300 USD) and December 2022 (8000 USD). This unexpected increase prompted us to conduct a thorough analysis to understand the factors contributing to this cost surge.
Analysing the Problem
Initially, we began our investigation by reevaluating our existing application architecture and its associated data load. Concurrently, we utilised the AWS Cost Explorer tool to gain a more detailed breakdown of the RDS cost.
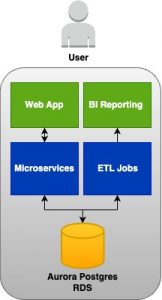
The diagram illustrates that we were employing a single Database (DB) to manage both our Web application data load and Reporting ETL data load. This meant that a single RDS Aurora Postgres instance handled all data storage and processing load. Additionally, in December, three new customers joined our platform, and their data volumes were significantly larger compared to the four existing customers.
The Cost Explorer analysis revealed a direct correlation between the increased data load from the new customers and the rising I/O requests in the Aurora Postgres database, which served as the primary cost driver. The diagram below depicts the substantial surge in I/O operations during this period. Our final conclusion was that the influx of data from the new customers led to extensive processing time and necessitated a large number of I/O operations in DB.
In light of these findings, we promptly recognised the need to make architectural changes to address scalability issues and optimise costs effectively.
Realising the Solution
The optimal resolution entails a twofold approach: reducing RDS costs and enhancing application architecture scalability. To achieve cost reduction, we must transition to a different RDS type with a more suitable costing strategy than Aurora Postgres, aligning precisely with our requirements. Moreover, to bolster scalability, it is imperative to decouple the reporting data processing, or the ETL process, from the Web app DB. By implementing these strategic changes, we can attain a more cost-effective and scalable solution for our application.
Upon careful analysis of RDS costing, it became evident that Postgres RDS emerged as the superior choice for handling heavy data processing compared to Aurora Postgres in our use case. The following cost-related factors elucidate why it was the more favorable option:
- Aurora Postgres: 0.20$ per 1 million I/O requests
- RDS Postgres: $0.116 per IOPS-month of provisioned io1 IOPS (input/output operations per second)
Another key factor is that, we can configured how much IOPS we need to provision in our Postgres RDS instance. Let’s take this example I took from AWS EBS Cost;
For example, let’s say that you provision a 2,000 GB volume for 12 hours (43,200 seconds) in a 30-day month. In a region that charges $0.125 per GB-month, you would be charged $4.167 for the volume ($0.125 per GB-month * 2,000 GB * 43,200 seconds / (86,400 seconds/day * 30-day month)).
Additionally, you provision 1,000 IOPS for your volume. In a region that charges $0.065 per provisioned IOPS-month, you would be charged $1.083 for the IOPS that you provisioned ($0.065 per provisioned IOPS-month * 1,000 IOPS provisioned * 43,200 seconds /(86,400 seconds /day * 30-day month)).
For this example, the charges would be:
$5.25 ($4.167 + $1.083).
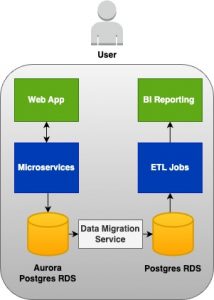
Replication via AWS Data Migration Service (DMS)
Upon settling on the decision to utilise RDS Postgres as the reporting database, the subsequent challenge arose: devising a way to establish data replication between the Aurora DB and the Reporting RDS DB. Given that these two were distinct DB instance types and necessitated Master – Master data replication, we embarked on evaluating several AWS services.
After careful consideration, we opted for the AWS Data Migration Service (DMS) to facilitate the one-way data replication from the Web App DB to the Reporting DB. The appeal of DMS lies in its fully managed nature by AWS, which translates to zero operational costs. Consequently, we proceeded with DMS and, to date, have encountered no issues with the replication process.
Finally, by combining all the aforementioned components, we successfully realised our desired architecture, as illustrated in the image below.
Final Outcome and Learnings
Our primary objective was to decrease the RDS cost. By February, following the aforementioned modifications, we achieved a remarkable 140% reduction in RDS expenses. The diagram below clearly demonstrates the significant decrease in RDS costs.
Furthermore, this architectural alteration not only led to substantial cost reduction but also significantly enhanced the stability of our application. The full decoupling of the Web App DB from the Reporting Data load ensured that user interactions with the application would not interfere with ETL data load processing, resulting in improved overall application stability.
An essential lesson learned from this experience is the importance of continuously reassessing the architecture during periods of business growth. Making precise design choices promptly and adeptly in response to rapid changes is imperative to achieving and sustaining successful outcomes.
Through this article, I aimed to share my experiences on effectively optimising RDS costs while supporting business growth. I intend to build on this knowledge by presenting more use cases in the forthcoming months as part of my article series, ‘Initiate your SaaS journey by taking small steps and steadily enhancing capabilities with AWS‘. I hope these future articles will provide valuable insights to readers, guiding them in their own SaaS journey and AWS implementation.